











Java岗大厂面试百日冲刺【Day7】 —— 数据库2(事务)
编辑
Java岗大厂面试百日冲刺【Day7】 —— 数据库2(事务)
本文已获得原作者 _陈哈哈 授权并经过重新整理规划后发布。
本栏目Java开发岗高频面试题主要出自以下各技术栈:Java基础知识、集合容器、并发编程、JVM、Spring全家桶、MyBatis等ORMapping框架、MySQL数据库、Redis缓存、RabbitMQ消息队列、Linux操作技巧等。
面试题1:先说一下什么是MySQL事务吧
简单说,事务就是一组原子性的SQL执行单元。如果数据库引擎能够成功地对数据库应 用该组査询的全部语句,那么就执行该组SQL。如果其中有任何一条语句因为崩溃或其他原因无法执行,那么所有的语句都不会执行。要么全部执行成功(commit),要么全部执行失败(rollback)。
这里引用银行转账的例子,假设银行的数据库有两张表:信用卡(credit)表和储蓄(savings)表。用户陈哈哈要把信用卡里最后100块钱额度转到他 的储蓄账户用来吃饭,那么需要至少三个步骤:
- 检査信用卡余额是否髙于100块钱。
- 从信用卡账户余额中减去100块钱。
- 在储蓄账户余额中增加100块钱。
上述三个步骤必须在同一个事务中执行,任何一个SQL失败,则必须回滚所有的SQL。这里用START TRANSACTION语句开启事务,要么使用COMMIT提交事务将修改的数据持久保留,要么使用ROLLBACK销所有的修改。事务SQL的样本如下:
START TRANSACTION;
-- 检查信用卡账户额度
SELECT balance FROM credit WHERE customer_id = 'chenhh';
-- 信用卡表扣钱
UPDATE credit SET balance = balance - 100.00 WHERE customer_id = 'chenhh';
-- 储蓄表加钱
UPDATE savings SET balance = balance + 100.00 WHERE customer_id = 'chenhh';
COMMIT;
试想一下,如果执行到第四条语句时服务器崩溃了,会发生什么?废话,我被坑了100块钱,中午只能饿肚子!再假如,在执行到第三条语句和第四 条语句之间时,同一时间,另外一个进程,来自商场结账的女朋友,也要信用卡账户的100块,那么结果可能就是银行在不知道这个逻辑的情况下白白给了女朋友100块钱?
说一下你对ACID四大特性的理解
ACID特性:原子性、一致性、隔离性、持久性
原子性(Atomicity)
单个事务,为一个不可分割的最小工作单元,整个事务中的所有操作要么全部commit成功,要么全部失败rollback,对于一个事务来说,不可能只执行其中的一部分SQL操作,这就是事务的原子性。
一致性(Consistency)
数据库总是从一个一致性的状态转换到另外一个一致性的状态。在前面的例子中, 一致性确保了,即使在执行第三、四条语句之间时系统崩潰,信用卡账户也不会损 失100块,因为事务最终没有提交,所以事务中所做的修改也不会保存到数据库中,保证数据一致性。
隔离性(Isolation)
通常来说,一个事务所做的修改在最终提交以前,对其他事务是不可见的。在前面 的例子中,当执行完第三条语句、第四条语句还未开始时,此时有另外一个账户查询余额SQL开始运行,则其看到的信用卡账户的余额并没有被减去100元。后面我们讨论隔离级别(Isolation level)的时候,会发现为什么我们要说事务通常来说是不可见的。
持久性(Durability)
一旦事务提交,则其所做的修改就会永久保存到数据库中。此时即使系统崩溃,修改的数据也不会丢失。
事务的ACID特性可以确保银行不会弄丢你的钱。而在应用逻辑中,要实现这一点非常难, 甚至可以说是不可能完成的任务。一个兼容ACID的数据库系统,需要做很多复杂但可能用户并没有觉察到的工作,才能确保ACID的实现。
可以从原理上聊一下ACID具体是怎么实现的么?
对MySQL来说,逻辑备份日志(binlog)、重做日志(redolog)、回滚日志(undolog)、锁技术 + MVCC就是MySQL实现事务的基础。
- 原子性:通过undolog来实现。
- 持久性:通过binlog、redolog来实现。
- 隔离性:通过(读写锁+MVCC)来实现。
- 一致性:
MySQL通过原子性,持久性,隔离性最终实现(或者说定义)数据一致性。
1、原子性原理
事务通常是以BEGIN TRANSACTION 开始,以 COMMIT 或 ROLLBACK 结束。
COMMIT表示提交,即提交事务的所有操作并持久化到数据库中。ROLLBACK表示回滚,即在事务中运行的过程中发生了某种故障,事务不能继续执行,系统将事务中对数据库所有已完成的操作全部撤销,回滚到事务开始时的状态,这里的操作指对数据库的更新操作,已执行的查询操作不用管。这时候也就需要用到 undolog 来进行回滚。- undolog:
- 每条数据变更(INSERT/UPDATE/DELETE/REPLACE)等操作都会生成一条undolog记录,在SQL执行前先于数据持久化到磁盘。
- 当事务需要回滚时,MySQL会根据回滚日志对事务中已执行的SQL做逆向操作,比如 DELETE 掉一行数据的逆向操作就是再把这行数据 INSERT回去,其他操作同理。
2、持久性原理
先了解一下MySQL的数据存储机制,MySQL的表数据是存放在磁盘上的,因此想要存取的时候都要经历磁盘 IO,然而即使是使用 SSD 磁盘 IO 也是非常消耗性能的。为此,为了提升性能 InnoDB 提供了缓冲池(Buffer Pool),Buffer Pool 中包含了磁盘数据页的映射,可以当做缓存来使用:
- 读数据:会首先从缓冲池中读取,如果缓冲池中没有,则从磁盘读取在放入缓冲池;
- 写数据:会首先写入缓冲池,缓冲池中的数据会定期同步到磁盘中;
我们知道,MySQL表数据是持久化到磁盘中的,但如果所有操作都去操作磁盘,等并发上来了,那处理速度谁都吃不消,因此引入了缓冲池(Buffer Pool)的概念,Buffer Pool 中包含了磁盘中部分数据页的映射,可以当做缓存来用;这样当修改表数据时,我们把操作记录先写到Buffer Pool中,并标记事务已完成,等MySQL空闲时,再把更新操作持久化到磁盘里(你可能会问,到底什么时候执行持久化呢?1、MySQL线程低于高水位;2、当有其他查询、更新语句操作该数据页时),从而大大缓解了MySQL并发压力。
但是它也带来了新的问题,当MySQL系统宕机,断电时Buffer Pool数据不就丢了?
因为我们的数据已经提交了,但此时是在缓冲池里头,还没来得及在磁盘持久化,所以我们急需一种机制需要存一下已提交事务的数据,为恢复数据使用。
于是 redo log + binlog的经典组合就登场了,这里不在扩展赘述。可参考《听我讲完redo log、binlog原理,面试官老脸一红》
3、隔离性原理
隔离性是事务ACID特性里最复杂的一个。在SQL标准里定义了四种隔离级别,每一种级别都规定一个事务中的修改,哪些是事务之间可见的,哪些是不可见的。
级别越低的隔离级别可以执行越高的并发,但同时实现复杂度以及开销也越大。
Mysql 隔离级别有以下四种(级别由低到高):
| 隔离级别 | 效果 |
|---|---|
| 读未提交(RU) | 一个事务还没提交时,它做的变更就能被别的事务看到。(别的事务指同一时间进行的增删改查操作) |
| 读提交(RC) | 一个事务提交(commit)之后,它做的变更才会被其他事务看到。 |
| 可重复读(RR) | 一个事务执行过程中看到的数据,总是跟这个事务在启动时看到的数据是一致的。当然在可重复读隔离级别下,未提交变更对其他事务也是不可见的。 |
| 串行(xíng)化(S) | 正如物理书上写的,串行是单线路,顾名思义在MySQL中同一时刻只允许单个事务执行,“写”会加“写锁”,“读”会加“读锁”。当出现读写锁冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行。 |
搞懂了隔离级别以及实现原理其实就可以理解ACID里的隔离性了。前面说过原子性,隔离性,持久性的目的都是为了要做到一致性,但隔离型跟其他两个有所区别,原子性和持久性是为了要实现数据的正确、可用,比如要做到宕机后的恢复、事务的回滚等,保证数据是正确可用的!
那么隔离性是要做到什么呢?
隔离性要管理的是:多个并发读写请求(事务)过来时的执行顺序。像交警在马路口儿指挥交通一样,当并发处理多个DML更新操作时,如何让事务操作他该看到的数据,出现多个事务处理同一条数据时,让事务该排队的排队,别插队捣乱,保证数据和事务的相对隔离,这就是隔离性要干的事儿。
所以,从隔离性的实现原理上,我们可以看出这是一场数据的可靠性与性能之间的权衡。
4、一致性原理
一致性,我们要保障的是数据一致性,数据库中的增删改操作,使数据库不断从一个一致性的状态转移到另一个一致性的状态。
事务该回滚的回滚,该提交的提交,提交后该持久化磁盘的持久化磁盘,该写缓冲池的写缓冲池+写日志;对于数据可见性,通过四种隔离级别进行控制,使得库表中的有效数据范围可控,保证业务数据的正确性的前提下,进而提高并发程度,支撑服务高QPS的稳定运行,保证数据的一致性,这就是咱们叨叨叨说的清楚想不明白的数据库ACID四大特性。
面试题2:并发场景下事务会存在哪些数据问题?
并发场景下MySQL事务可能会出现脏读、幻读、不可重复读问题;
脏读(Drity Read):某个事务已更新一份数据,另一个事务在此时读取了同一份数据,由于某些原因,前一个RollBack了操作,则后一个事务所读取的数据就会是不正确的。不可重复读(Non-repeatable read):在一个事务的两次查询之中数据不一致,这可能是两次查询过程中间插入了一个事务更新了原有的数据。幻读(Phantom Read):在一个事务的两次查询中数据笔数不一致,例如有一个事务查询了几列(Row)数据,而另一个事务却在此时插入了新的几列数据,先前的事务在接下来的查询中,就会发现有几列数据是它先前所没有的。
那Innodb是如何解决幻读问题的呢?
先说结论,MySQL 存储引擎 InnoDB 在可重复读(RR)隔离级别下是解决了幻读问题的。
方法是通过next-key lock在当前读事务开启时,1.给涉及到的行加写锁(行锁)防止写操作;2.给涉及到的行两端加间隙锁(Gap Lock)防止新增行写入;从而解决了幻读问题。
- 幻读出现的场景:
幻读出现在可重复读(RR)隔离级别下,普通的SELECT查询就是快照读,是不会看到别的事务插入的数据的。因此,幻读在“当前读”下才会出现。(当前读会生成行锁,但行锁只能锁定存在的行,针对新插入的操作没有限定)
上面 session B 的修改结果,被 session A 之后的 select 语句用“当前读”看到,不能称为幻读。幻读仅专指“新插入的行”。
因为这三个查询都是加了 for update,都是当前读。而当前读的规则,就是要能读到所有已经提交的记录的最新值。并且,session B 和 sessionC 的两条语句,执行后就会提交,所以 Q2 和 Q3 就是应该看到这两个事务的操作效果,而且也看到了,这跟事务的可见性规则并不矛盾。
幻读场景实例:
测试表数据如下:
mysql> select * from LOL;
+----+--------------+--------------+-------+
| id | hero_title | hero_name | price |
+----+--------------+--------------+-------+
| 1 | 刀锋之影 | 泰隆 | 6300 |
| 2 | 迅捷斥候 | 提莫 | 6300 |
| 3 | 光辉女郎 | 拉克丝 | 1350 |
| 4 | 发条魔灵 | 奥莉安娜 | 6300 |
| 5 | 至高之拳 | 李青 | 6300 |
| 6 | 无极剑圣 | 易 | 450 |
| 7 | 疾风剑豪 | 亚索 | 6300 |
+----+--------------+--------------+-------+
7 rows in set (0.00 sec)
下面是一个出现幻读情况的示例流程:
| 时刻T | Session A | Session B | Session C |
|---|---|---|---|
| T1 | begin;– Query1select * from LOL where price=450 for update;Result:(6,‘无极剑圣’,450) | ||
| T2 | update LOL set price=450 where hero_title = ‘疾风剑豪’; | ||
| T3 | – Query2select * from LOL where price=450 for update;Result:(6,‘无极剑圣’,450),(7,‘疾风剑豪’,450) | ||
| T4 | insert into LOL values(10,‘雪人骑士’,‘努努’,‘450’); | ||
| T5 | – Query3select * from LOL where price=450 for update;Result:(6,‘无极剑圣’,450),(7,‘疾风剑豪’,450),(10,‘雪人骑士’,450) | ||
| T6 | commit; |
可以看到,session A 里执行了三次查询,分别是 Q1、Q2 和 Q3。它们的 SQL 语句相同,都是 select * from LOL where price=450 for update。这个语句的意思你应该很清楚了,查所有 price=450 的行,而且使用的是当前读,并且加上写锁。现在,我们来看一下这三条 SQL 语句,分别会返回什么结果。
- Q1 只返回 “无极剑圣” 这一行;
- 在 T2 时刻,session B 把 “疾风剑豪” 这一行的 price 值改成了 450,因此 T3 时刻 Q2 查出来的是 “无极剑圣” 和 “疾风剑豪” 这两行;
- 在 T4 时刻,session C 又插入一行 (10,‘雪人骑士’,‘努努’,‘450’),因此 T5 时刻 Q3 查出来 price = 450 的是"无极剑圣" 、“疾风剑豪” 和 “雪人骑士” 这三行。
其中,Q3 读到 (10,‘雪人骑士’,450) 这一行的现象,被称为“幻读”。也就是说,幻读指的是一个事务在前后两次查询同一个范围的时候,后一次查询看到了前一次查询没有看到的行。
解决幻读原理分析
场景如上,场景隔离级别为RR,当前读。
- 一、原理解读
那么幻读能仅通过行锁解决么?答案是否定的,如上面示例,首先说明一下,select xx for update(当前读)是将所有条件涉及到的(符合where条件)行加上行锁。但是,就算我在select xx for update 事务开启时将所有的行都加上行锁。那么也锁不住Session C新增的行,因为在我给数据加锁的时刻,压根就还没有新增的那行,自然也不会给新增行加上锁。
所以要解决幻读,就必须得解决新增行的问题。
现在你应该明白了,产生幻读的原因是:行锁只能锁住行,但是新插入记录这个动作,要更新的是记录之间的“间隙”。因此,为了解决幻读问题,InnoDB 只好引入新的锁,也就是间隙锁 (Gap Lock)。顾名思义,间隙锁,锁的就是两个值之间的空隙。比如文章开头的表 LOL,初始化插入了 7 个记录,这就产生了 8 个间隙。

- 二、next-key lock
这样,当你执行 select * from LOL where hero_title = ‘疾风剑豪’ for update 的时候,就不止是给数据库中已有的 7 个记录加上了行锁,还同时加了 8 个间隙锁。这样就确保了无法再插入新的记录,也就是Session C在T4新增(10,‘雪人骑士’,‘努努’,‘450’) 行时,由于ID大于7,被间隙锁(7,+∞)锁住。
在一行行扫描的过程中,不仅将给行加上了行锁,还给行两边的空隙,也加上了间隙锁。MySQL将行锁 + 间隙锁组合统称为 next-key lock,通过 next-key lock 解决了幻读问题。
注意:
next-key lock的确是解决了幻读问题,但是next-key lock在并发情况下也经常会造成死锁。死锁检测和处理也会花费时间,一定程度上影响到并发量。
面试题3:说一下MySQL中你都知道哪些锁?
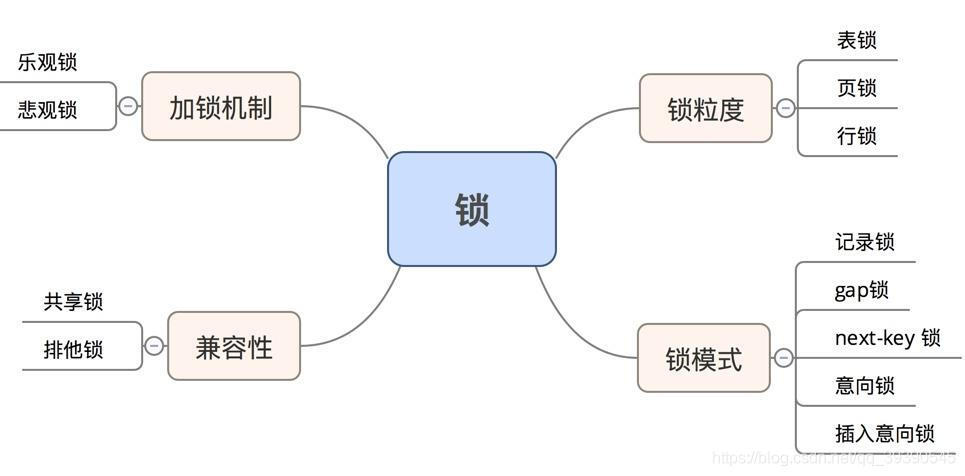
- 按锁粒度从大到小分类:表锁,页锁和行锁;以及特殊场景下使用的全局锁
- 如果按锁级别分类则有:共享(读)锁、排他(写)锁、意向共享(读)锁、意向排他(写)锁;
- 以及Innodb引擎为解决幻读等并发场景下事务存在的数据问题,引入的Record Lock(行记录锁)、Gap Lock(间隙锁)、Next-key Lock(Record Lock + Gap Lock结合)等;
- 还有就是我们面向编程的两种锁思想:悲观锁、乐观锁。
那你来谈一谈你对表锁、行锁的理解吧?
表锁
表级别的锁定是MySQL各存储引擎中最大颗粒度的锁定机制。该锁定机制最大的特点是实现逻辑非常简单,带来的系统负面影响最小。所以获取锁和释放锁的速度很快。由于表级锁一次会将整个表锁定,所以可以很好的避免困扰我们的死锁问题。
当然,锁定颗粒度大所带来最大的负面影响就是出现锁定资源争用的概率也会最高,大大降低并发度。
使用表级锁定的主要是MyISAM,MEMORY,CSV等一些非事务性存储引擎。
行锁
与表锁正相反,行锁最大的特点就是锁定对象的颗粒度很小,也是目前各大数据库管理软件所实现的锁定颗粒度最小的。由于锁定颗粒度很小,所以发生锁定资源争用的概率也最小,能够给予应用程序尽可能大的并发处理能力从而提高系统的整体性能。
虽然能够在并发处理能力上面有较大的优势,但是行级锁定也因此带来了不少弊端。由于锁定资源的颗粒度很小,所以每次获取锁和释放锁需要做的事情也更多,带来的消耗自然也就更大了。此外,行级锁定也最容易发生死锁。
使用行级锁定的主要是InnoDB存储引擎。
适用场景:从锁的角度来说,表级锁更适合于以查询为主,只有少量按索引条件更新数据的应用,如Web应用;而行级锁则更适合于有大量按索引条件并发更新数据的情况,同时又有并发查询的应用场景。
页锁
除了表锁、行锁外,MySQL还有一种相对偏中性的页级锁,页锁是MySQL中比较独特的一种锁定级别,在其他数据库管理软件中也并不是太常见。页级锁定的特点是锁定颗粒度介于行级锁定与表级锁之间,所以获取锁定所需要的资源开销,以及所能提供的并发处理能力也同样是介于上面二者之间。另外,页级锁定和行级锁定一样,会发生死锁。
那全局锁是什么时候用的呢?
首先全局锁,是对整个数据库实例加锁。使用场景一般在全库逻辑备份时。
MySQL提供加全局读锁的命令:Flush tables with read lock (FTWRL)
这个命令可以使整个库处于只读状态。使用该命令之后,数据更新语句、数据定义语句和更新类事务的提交语句等修改数据库的操作都会被阻塞。
风险:
- 如果在主库备份,在备份期间不能更新,业务停摆
- 如果在从库备份,备份期间不能执行主库同步的binlog,导致主从延迟同步
还有一种锁全局的方式:set global readonly=true ,相当于将整个库设置成只读状态,但这种修改global配置量级较重,和全局锁不同的是:如果执行Flush tables with read lock 命令后,如果客户端发生异常断开,那么MySQL会自动释放这个全局锁,整个库回到可以正常更新的状态。但将库设置为readonly后,客户端发生异常断开,数据库依旧会保持readonly状态,会导致整个库长时间处于不可写状态,试想一下微信只能看,不能打字~~
那你再说一下按锁级别划分的那几种锁的使用场景和理解吧?
MySQL基于锁级别又分为:共享(读)锁、排他(写)锁、意向共享(读)锁、意向排他(写)锁
对于共享(读)锁、排他(写)锁,比如咱们住酒店,入住前顾客都是有权看房的,只看不住想白嫖都是可以的,前台小姐姐会把门给你打开。
看房时房间相当于公共场所,小姐姐嘱咐不能乱涂乱画,也不能偷喝免费的矿泉水。。如果你觉得不错,偷偷跑到前台要定这间房,交钱后会给你这个房间的钥匙并将房间状态改为已入住,不再允许其他人看房(排他 写)。
对了,当办理入住时前台小姐姐也会通知看房的杀马特小伙子说这间房已经有人定了!!等看房的杀马特小伙儿骂骂咧咧出门后,看到满头大汗的你,鄙夷着咽了一口口水,咳tui!然后你锁上门哼着歌儿,开始干那些见不得人的事儿, 直到你退房前,其他人无法在看你的房。
可见,读锁是可以并发获取的(共享的),而写锁只能给一个事务处理(排他的)。当你想获取写锁时,需要等待之前的读锁都释放后方可加写锁;而当你想获取读锁时,只要数据没有被写锁锁住,你都可以获取到读锁,然后去看房。
另外还有意向读\写锁,严格来说他们并不是一种锁,而是存放表中所有行锁的信息。就像我们在酒店,当我们预定一个房间时,就对该行(房间)添加 意向写锁,但是同时会在酒店的前台对该行(房间)做一个信息登记(旅客姓名、男女、住多长时间、家里几头牛等)。大家可以把意向锁当成这个酒店前台,它并不是真正意义上的锁(钥匙),它维护表中每行的加锁信息,是共用的。后续的旅客通过酒店前台来看哪个房间是可选的,那么,如果没有意图锁,会出现什么情况呢?假设我要住房间,那么我每次都要到每一个房间看看这个房间有没有住人,显然这样做的效率是很低下的。杀马特小伙儿表示支持!
读写锁、意向锁的兼容性如下所示;
| 锁类型 | 读锁 | 写锁 | 意向读锁 | 意向写锁 |
|---|---|---|---|---|
| 读锁 | 兼容 | 冲突 | 兼容 | 冲突 |
| 写锁 | 冲突 | 冲突 | 冲突 | 冲突 |
| 意向读锁 | 兼容 | 冲突 | 兼容 | 兼容 |
| 意向写锁 | 冲突 | 冲突 | 兼容 | 兼容 |
我们再回到MySQL原理上讲
1、共享(读)锁(Share Lock)
共享锁,又叫读锁,是读取操作(SELECT)时创建的锁。其他用户可以并发读取数据,但在读锁未释放前,也就是查询事务结束前,任何事务都不能对数据进行修改(获取数据上的写锁),直到已释放所有读锁。
如果事务A对数据B(1024房)加上读锁后,则其他事务只能对数据B上加读锁,不能加写锁。获得读锁的事务只能读数据,不能修改数据。
SQL显示加锁写法:
SELECT … LOCK IN SHARE MODE;
在查询语句后面增加LOCK IN SHARE MODE,MySQL就会对查询结果中的每行都加读锁,当没有其他线程对查询结果集中的任何一行使用写锁时,可以成功申请读锁,否则会被阻塞。其他线程也可以读取使用了读锁的表,而且这些线程读取的是同一个版本的数据。
2、排他(写)锁(Exclusive Lock)
排他锁又称写锁、独占锁,如果事务A对数据B加上写锁后,则其他事务不能再对数据B加任何类型的锁。获得写锁的事务既能读数据,又能修改数据。
SQL显示加锁写法:
SELECT … FOR UPDATE;
在查询语句后面增加FOR UPDATE,MySQL 就会对查询结果中的每行都加写锁,当没有其他线程对查询结果集中的任何一行使用写锁时,可以成功申请写锁,否则会被阻塞。另外成功申请写锁后,也要先等待该事务前的读锁释放才能操作。
3、意向锁(Intention Lock)
意向锁属于表级锁,其设计目的主要是为了在一个事务中揭示下一行将要被请求锁的类型。InnoDB 中的两个表锁:
- 意向共享锁(IS):表示事务准备给数据行加入共享锁,也就是说一个数据行加共享锁前必须先取得该表的IS锁;
- 意向排他锁(IX):类似上面,表示事务准备给数据行加入排他锁,说明事务在一个数据行加排他锁前必须先取得该表的IX锁。
意向锁是 InnoDB 自动加的,不需要用户干预。
再强调一下,对于INSERT、UPDATE和DELETE,InnoDB 会自动给涉及的数据加排他锁;对于一般的SELECT语句,InnoDB 不会加任何锁,事务可以通过以下语句显式加共享锁或排他锁。
- 共享锁:SELECT … LOCK IN SHARE MODE;
- 排他锁:SELECT … FOR UPDATE;
- 0
- 0
-
赞助
 微信赞赏
微信赞赏
 支付宝赞赏
支付宝赞赏
-
分享